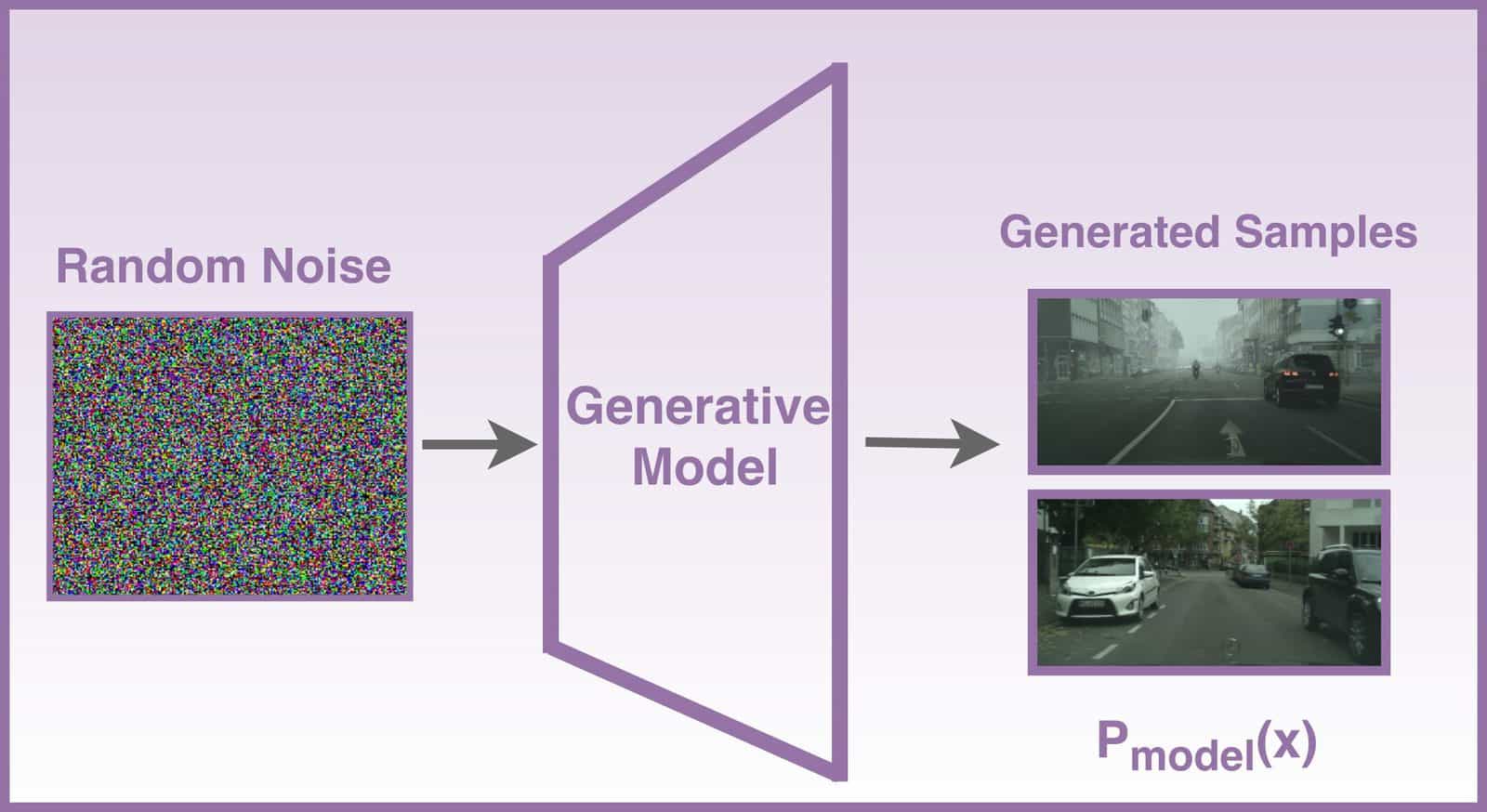
Generative Neural Networks
Generative models
Learn \(p_X\) given a set of training data \(x_i, \dots, x_n\)
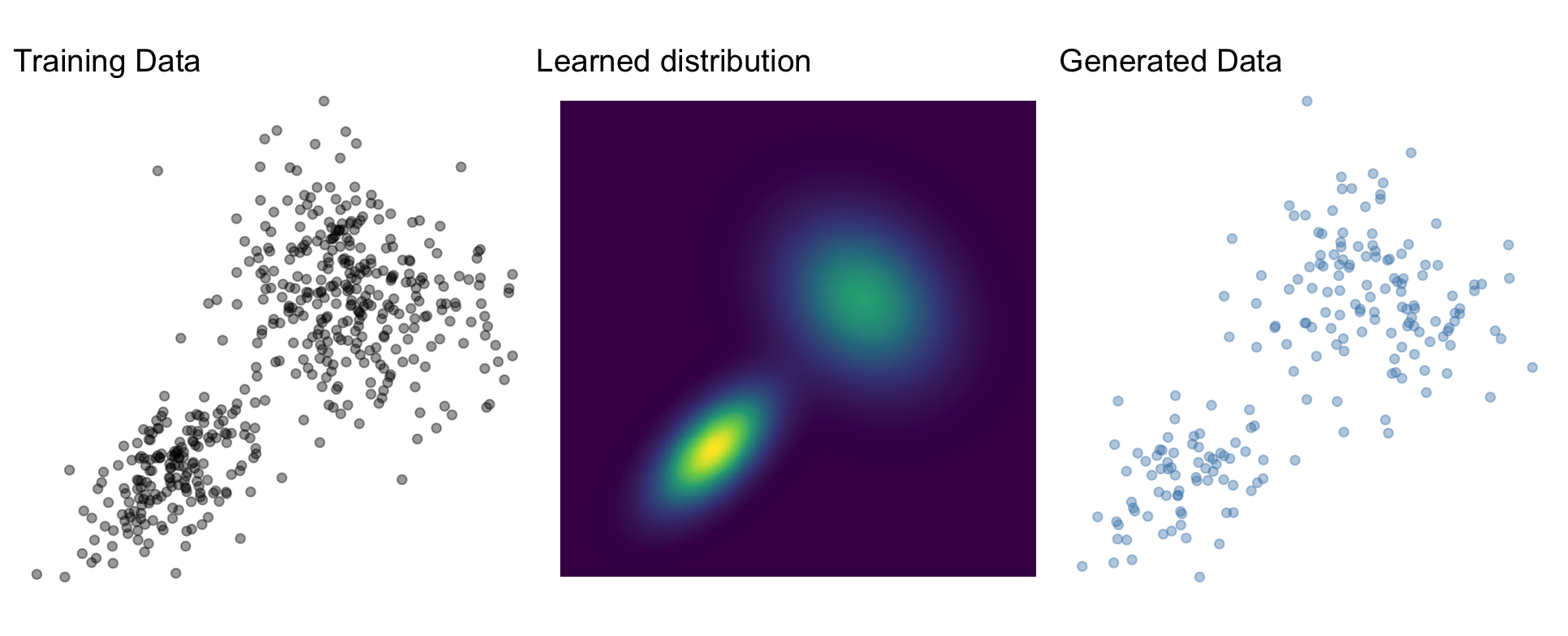
- Sampling \(x \sim p_X\)
- Density evaluation \(p_X(x)\)
Common idea
Map \(p_X\) to a base distribution \(p_Z\) through some operation \(g\)
\[ x \sim g(z) \text{ where } z \sim p_Z \]
Normalizing flows
Built on invertible transformations of random variables
- Find \(f\) such that \(f(X) = Z \sim \text{Normal}(0, I)\)
- \(f\) normalizes \(X\)
\(f\)

\[\rightarrow\]

Sampling
- Sample \(z \sim p_Z\) (e.g., Normal)
- Obtain \(x = f^{-1}(z)\)
\(f^{-1}\)
\[\leftarrow\]
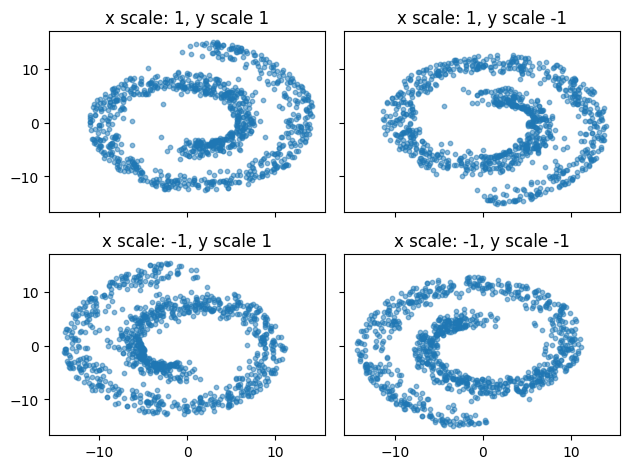
Change of variables - intuition
\[Z \sim \text{Uniform}(0, 1)\]

Change of variables - intuition
\[Z \sim \text{Uniform}(0, 1)\]
\[X = 2Z - 1\]
Change of variables - intuition
\[Z \sim \text{Uniform}(0, 1)\]
\[X = 2Z - 1\]

Flow composition
Invertible and differentiable functions are “closed” under composition
\[ f = f_L \circ f_{L-1} \circ \dots \circ f_1 \\ \]
\(f_1\)
\(f_2\)
\(f_3\)
\(\rightarrow\)

\(\rightarrow\)

\(\rightarrow\)
Flow composition - inverse
To invert a flow composition, we invert individual flows and run them in the opposite order
\[ f^{-1} = f_1^{-1} \circ f_2 ^{-1} \circ \dots \circ f_L^{-1} \\ \]
\(f_1^{-1}\)
\(f_2^{-1}\)
\(f_3^{-1}\)
\(\leftarrow\)
\(\leftarrow\)
\(\leftarrow\)
Coupling flow: Forward

Coupling flow: Inverse

Spline coupling (Müller et al., 2019)
- Transformation: Splines
- “Piecewise polynomials”
- More expressive
- Easier to overfit
- Slower at training and inference
![]()
Flow matching
- Defines a flow that transforms a distribution over time
- \(p_{t=0} = p_z\) - Base distribution
- \(p_{t=1} = q = p_x\) - Data distribution
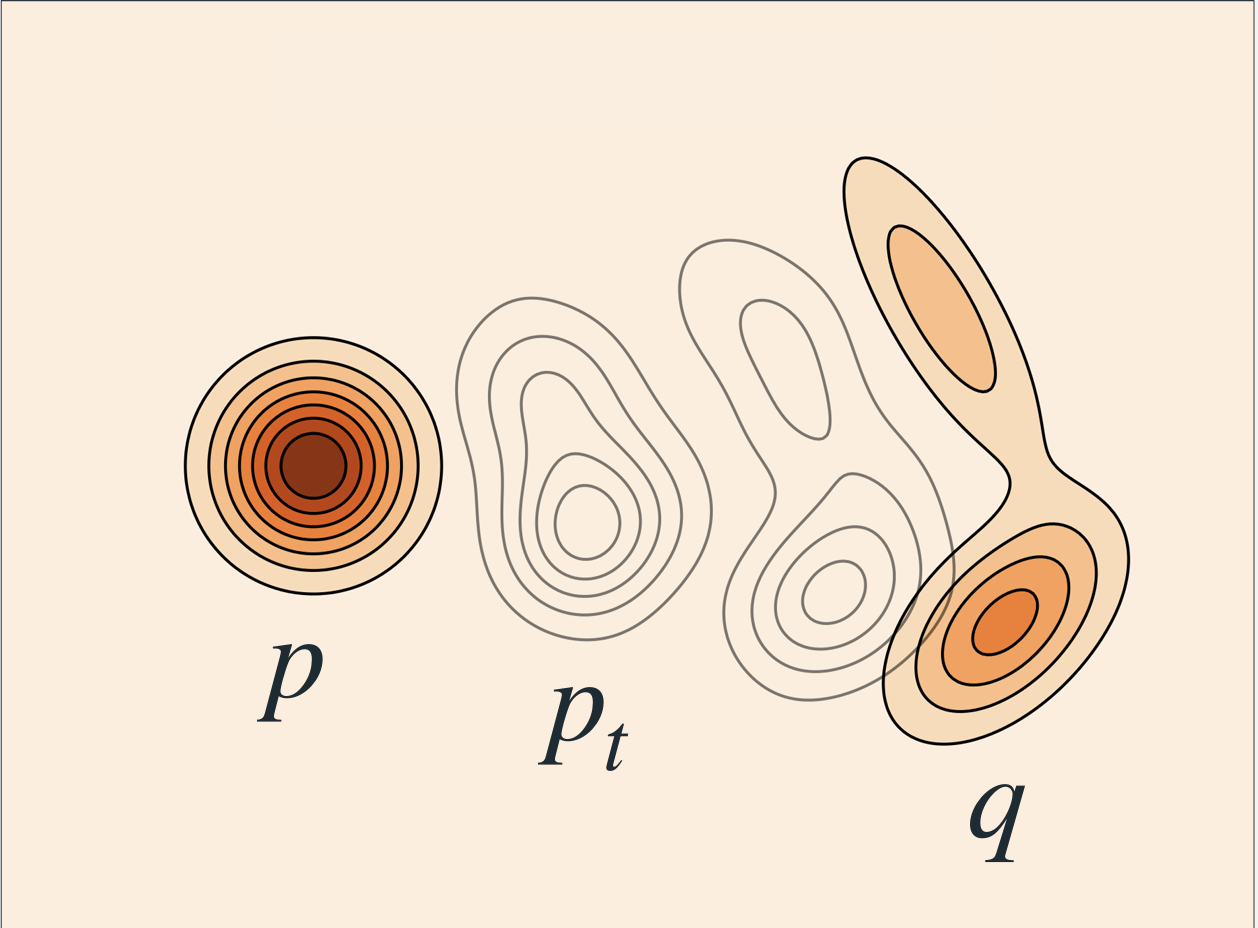
Lipman et al. (2024)
Flow and velocity
- Flow defines \(X_t = \phi_t(X_0)\)
- Time dependent vector field: \(\frac{d}{dt} \phi_t(x) = u_t(\phi_t(x))\)
- Model \(u_t\) with a neural network
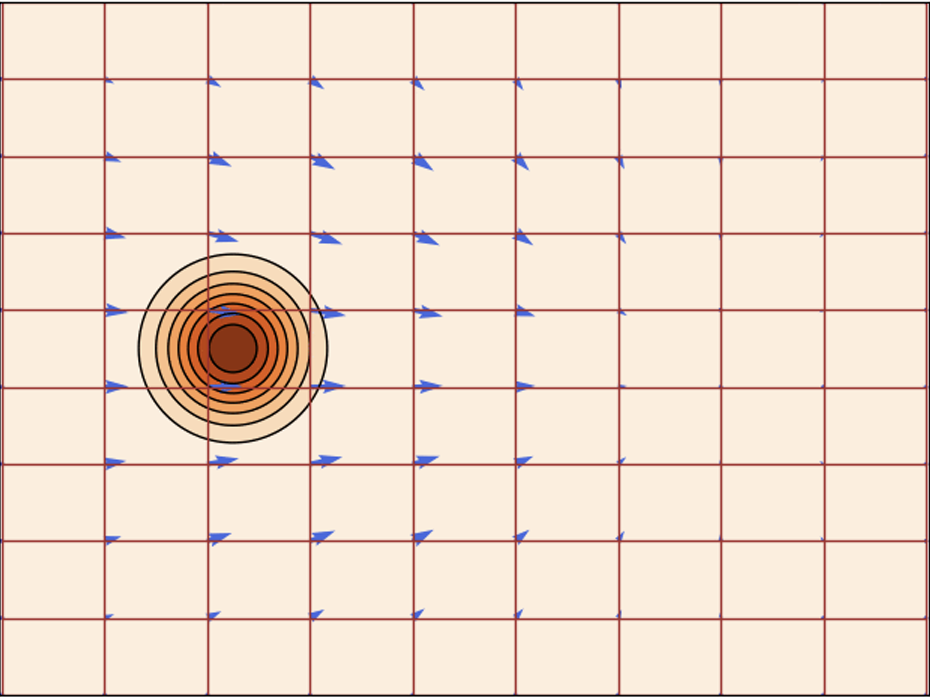
Lipman et al. (2024)
Flow matching
\[ \begin{aligned} \mathbb{E}_{t, X_t}|| u_{t,\theta}(X_t) - u_t(X_t) ||^2 \\ t\sim\text{Uniform}(0,1) \\ X_t \sim p_t(X_t) \end{aligned} \]
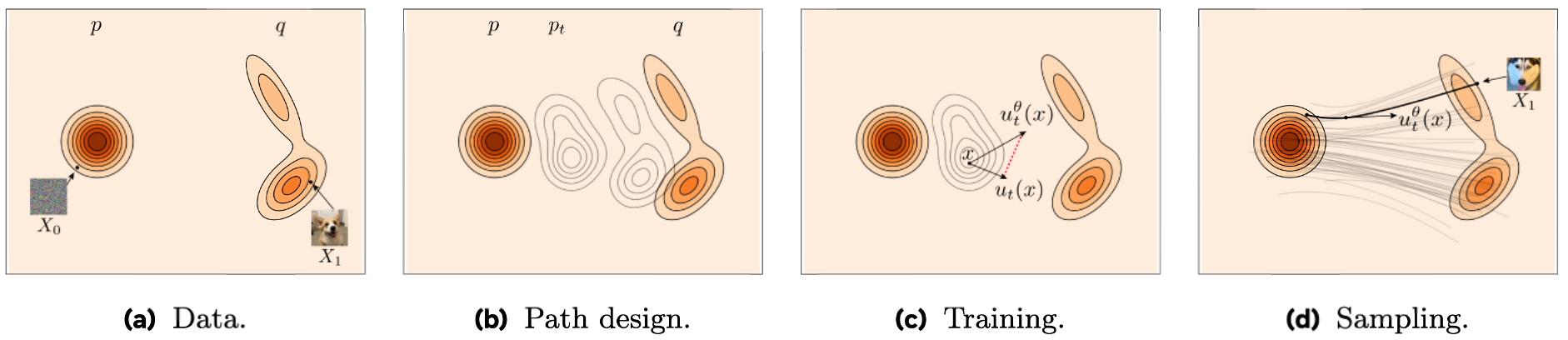
Lipman et al. (2024)
Conditional Flow Matching
Linear probability path
\[X_t = (1-t) X_0 + t X_1\]
Velocity
\[u_t(X_t \mid X_1, X_0) = X_1 - X_0\]
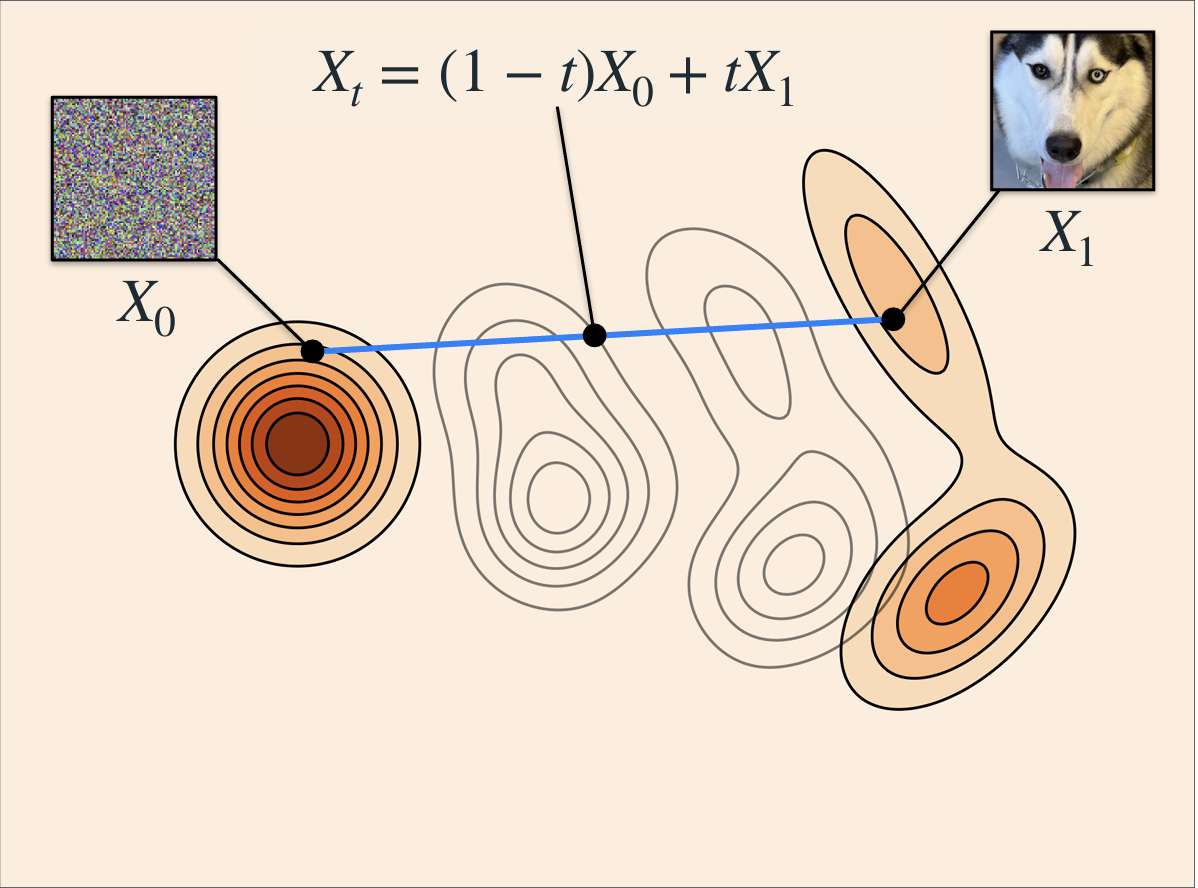
Lipman et al. (2024)
Conditional vs Marginal paths
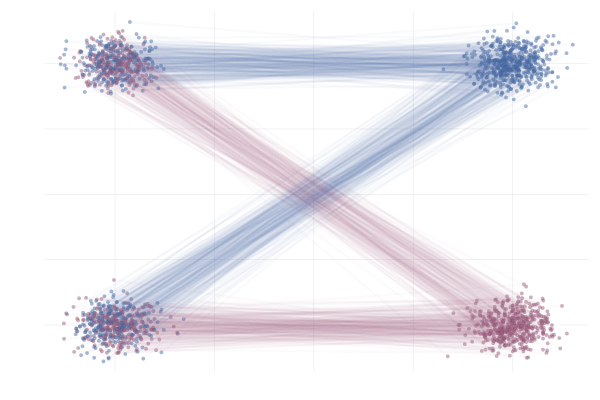

Optimal transport
- Independent coupling \(p(X_0, X_1) = p(X_0) p(X_1)\)
- Optimal transport coupling \(p(X_0, X_1) = \pi(X_0, X_1)\)
- Minimise transport cost (e.g., Wasserstein distance)
- For batches (Pooladian et al., 2023)
Figure 6: Fjelde et al. (2024)
Exercise