Deep Learning
Introduction

Shahab et al. (2024)
The anatomy of neural networks

Neuron
Regression + non-linear activation

Perceptron
Multiple regressions + non-linear activations
\[ \begin{aligned} z_k &= \sigma \Big(b_k + \sum_{j=1}^J W_{jk}x_j\Big)\\ z &= \sigma \Big(b + x W'\Big) \end{aligned} \]

Multi-Layer Perceptron
Multiple “layers” of perceptrons
Activation functions
\[ \tanh{(x)} = \frac{e^x - e^{-x}}{e^x + e^{-x}} \]

Activation functions
\[ \text{ReLU}(x) = \begin{cases} 0, x \leq 0 \\ x, x > 0\end{cases} \]

Activation functions
\[ \text{softplus}(x) = \log(1 + e^x) \]


Activation functions
\[ \sigma(x) = \frac{1}{1 + e^{-x}} \]

Activation functions
\[ \text{softmax}(x)_i = \frac{e^{x_i}}{\sum_{j=1}^{J} e^{x_j}} \]

Training networks
Minimise the loss with respect to the model parameters
\[ \operatorname*{argmin}_{\theta} \mathcal{L}(x; \theta) \]

Evaluating gradients
\[\Delta_\theta \mathcal{L}(x; \theta_n)\]

Backpropagation
\[ \frac{\partial \mathcal{L}}{\partial \theta_l} = \frac{\partial \mathcal{L}}{\partial z_L} \frac{\partial z_L}{\partial z_{L-1}} \dots \frac{\partial z_l}{\partial \theta_l} \]

Kernel trick
- Non-linear patterns in the data
- Project data into a higher-dimensional space
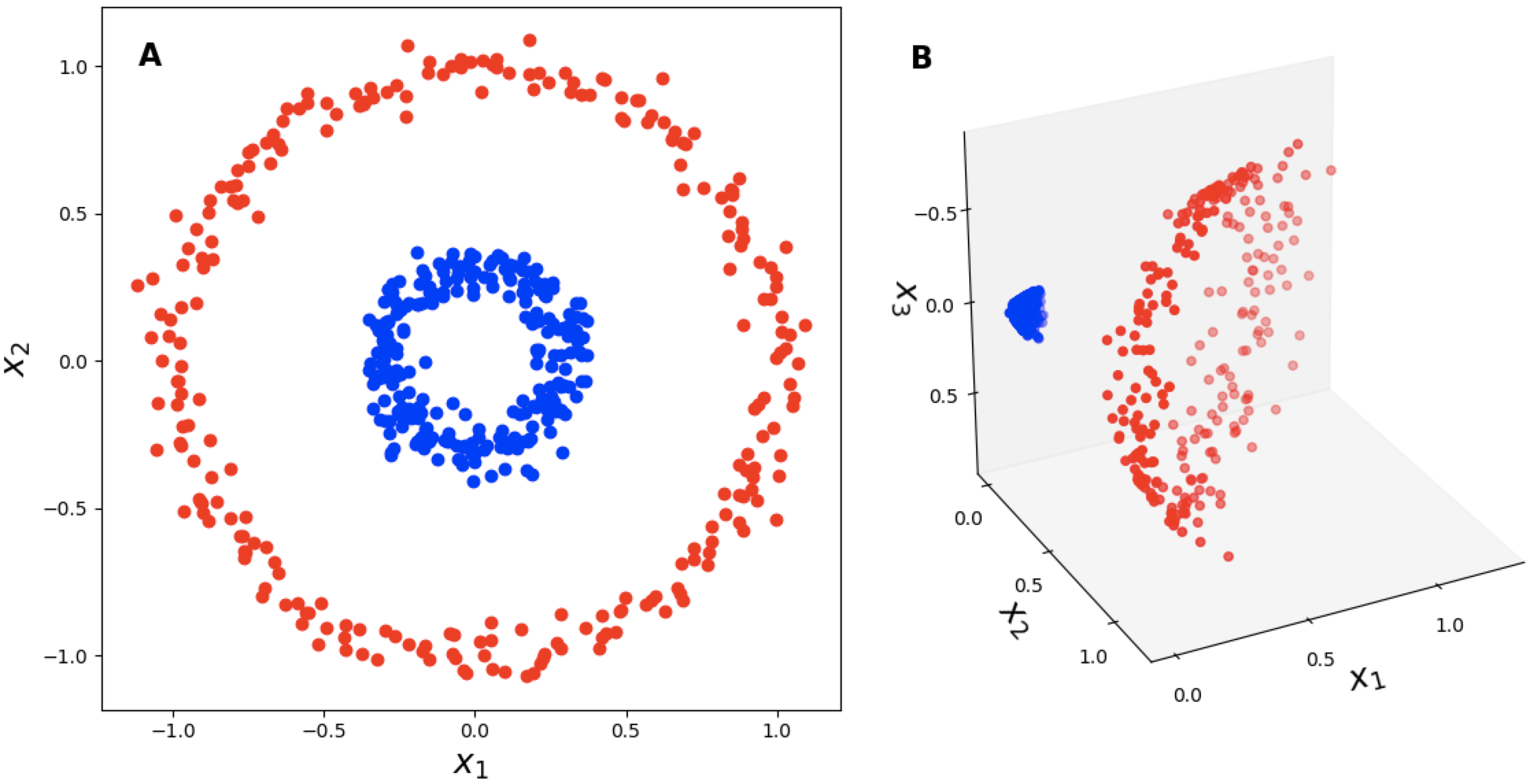
\(\rightarrow\) networks to add dimensions
Guards against overfiting
Large networks tend to overfit

Early stopping

Dropout
During training, “turn off” each activation with a probability \(p\)
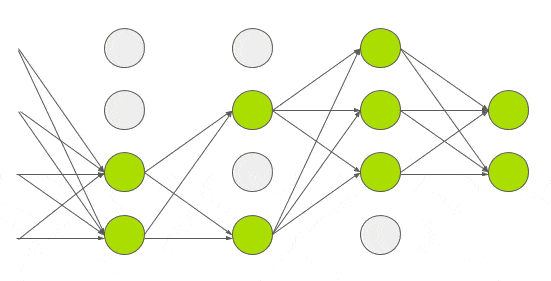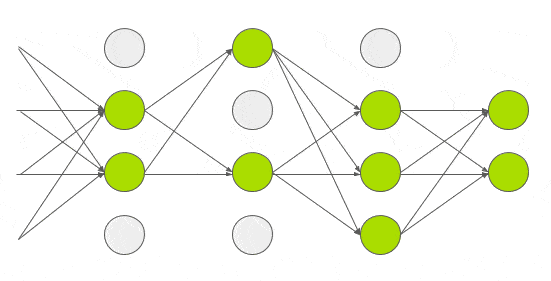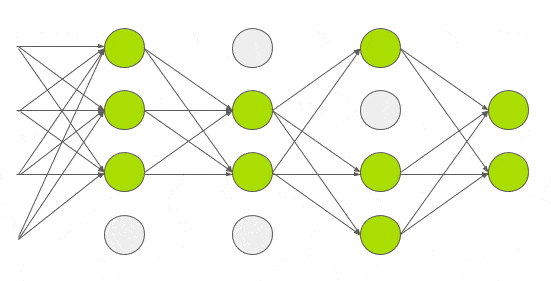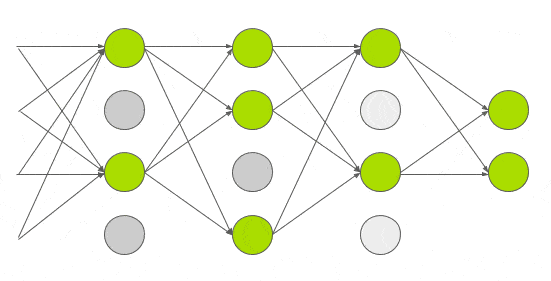
- Better generalization
- Reduced dependence on single neurons
- Reduced expressiveness
- Increased variance during training
Recurrent neural network (RNN)
- Works for sequences of different lengths
- Maintain a hidden state \(h_t = \sigma_h(W_h * h_{t-1} + W_x x_t + b_h)\)
- Output depends on hidden state \(y_t = \sigma_y(W_g * h_t + b_y)\)
Issues
- Sequential updating
- Limited long-term memory
- Vanishing gradient

Long short-term memory (LSTM)
- Learn to what to “forget” (forget gate) and what to “remember” (input gate)
- Cell state can carry over long term dependencies

Attention

Attention

Set architectures
- What if we do not have a fixed order?
- Instead, we have sets

Deep Set (Zaheer et al., 2017)
\[ f(X = \{ x_i \}) = \rho \left( \sigma(\tau(X)) \right) \]
- \(\tau\): Permutation equivariant function
- \(\sigma\): Permutation invariant pooling function (sum, mean)
- \(\rho\): Any function

Deep Set
